The tech landscape shifts fast. One year a framework is everywhere, the next year it fades into maintenance mode. But the underlying programming concepts 2026 demands are more stable. They outlast any…
10 Crucial Programming Concepts Every Developer Should Master in 2026
The tech landscape shifts fast. One year a framework is everywhere, the next year it fades into maintenance mode. But the underlying programming concepts 2026 demands are more stable. They outlast any…

How to Build a Real-Time Chat Application with WebSockets and Node.js
Real time communication changes how users interact with a web application. Instead of waiting for a page refresh, messages appear instantly. For chat apps, this is not a nice to have — it is the core…

The Future of Quantum Programming Languages in 2026
Quantum computing is steadily shifting from futuristic theory to practical reality. As we move into 2026, the landscape of quantum programming languages is evolving rapidly. Developers, researchers, a…

Getting Started with Rust for Systems Programming in 2026
Getting into systems programming with Rust in 2024 offers a fresh approach to writing safe and efficient code. Rust’s focus on memory safety and concurrency makes it a top choice for system-level task…
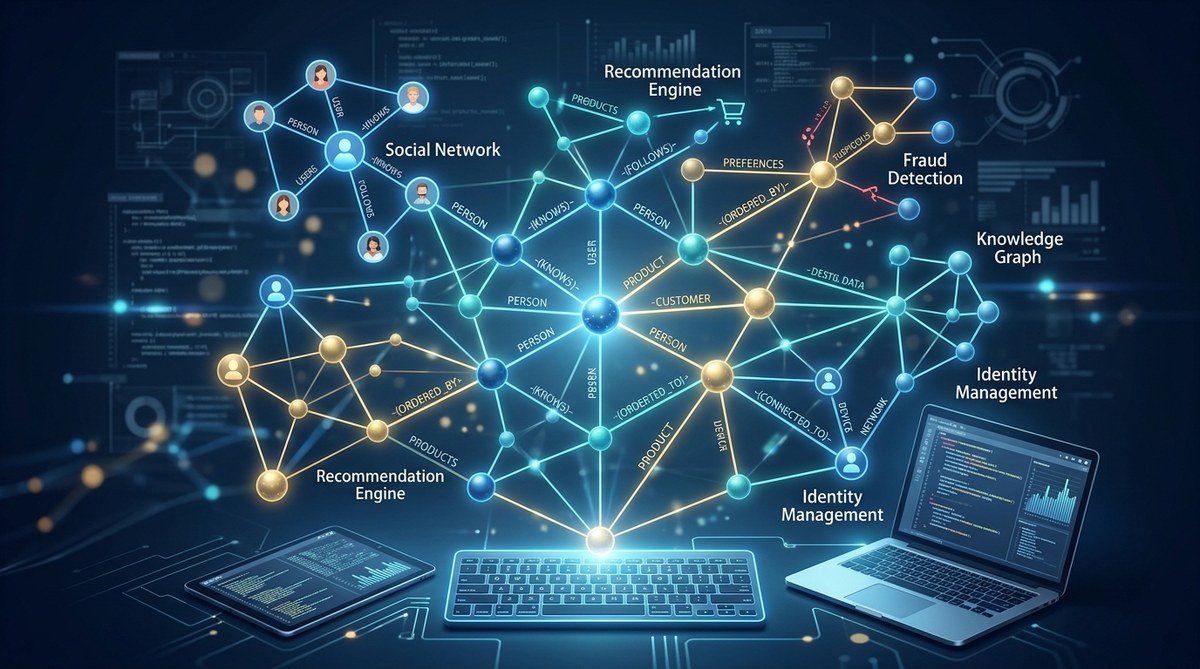
Exploring Graph Databases and Their Use Cases in Modern Development
Developers and data architects are increasingly turning to graph databases to handle complex, interconnected data. Unlike traditional relational systems, graph databases excel at modeling relationship…

Exploring the Latest Trends in Programming Languages for 2026
Software development is constantly shifting. Each year brings new languages, frameworks, and tools that redefine what’s possible. For 2024, understanding the current programming languages trends can g…

How to Evaluate and Select the Best Open Source Projects for Your Contributions
Contributing to open source can be a rewarding way to sharpen your skills, collaborate with others, and make an impact. But with thousands of projects out there, how do you find the right one to start…

Exploring Progressive Web Apps: How to Enhance User Experience and Performance
Websites and apps today face a constant demand for faster, more reliable, and engaging user experiences. Users expect seamless navigation, instant load times, and the convenience of offline access. Th…
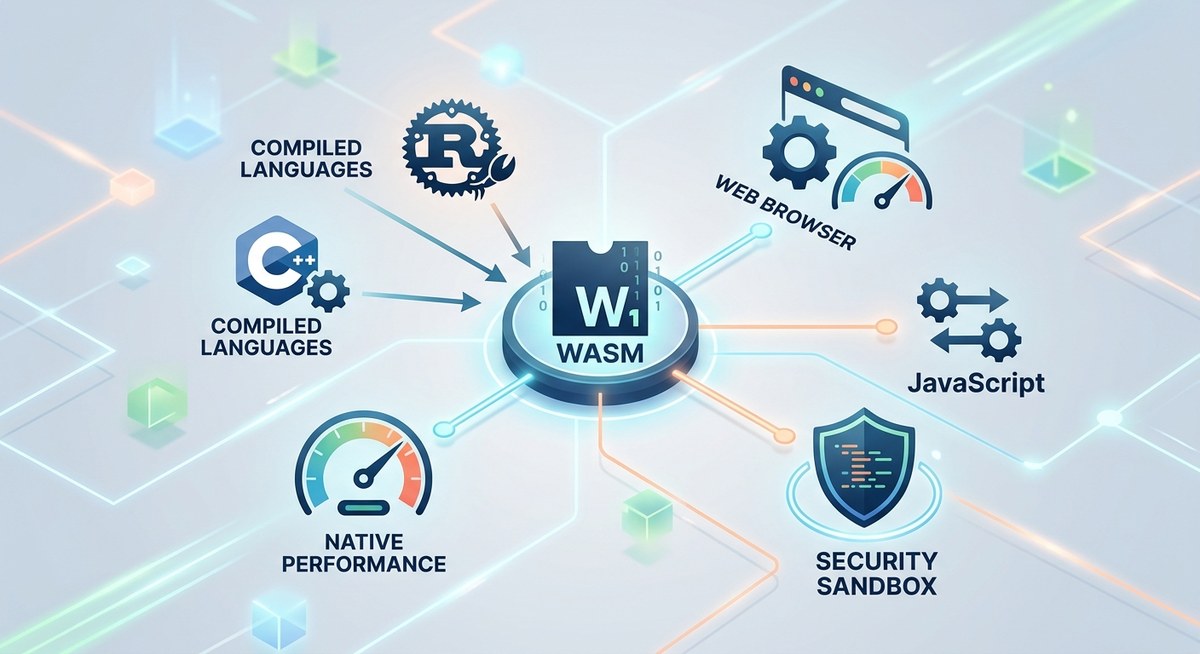
Understanding the Fundamentals of WebAssembly for Modern Web Development
WebAssembly is transforming the way web developers approach high-performance applications. It offers a way to run code at near-native speeds within browsers, opening new possibilities for interactive,…

Mastering Async Programming in JavaScript for Better Performance
JavaScript’s asynchronous programming capabilities are crucial for building fast, responsive applications. Mastering how to write non-blocking code lets you handle multiple tasks simultaneously, impro…